This article focuses on Demystifying Smart Contracts & Auditing and is the first part of the audit course. See primer here.
Behind the Scenes of Auditing Smart Contracts
This article series is targeted to an audience comprised of seasoned blockchain security professionals.
As discussed in the primer blog, we at BlockApex have picked the flag to lead the standardization of an advanced knowledge base for blockchain security.
It is now common knowledge that Solidity is a contract-oriented programming language used to write smart contracts on Ethereum Blockchain, so let’s start and ponder over the several phases the solidity smart contracts goes through before its equivalent bytecode is generated and is ultimately stored on the EVM.
Solidity Code
The process begins with the developer writing Solidity code. This code can be written in the Solidity programming language and may contain bugs, vulnerabilities, or other syntactical, semantical, logical, or run-time issues.
The Solidity compilation process involves several stages of transformation, analysis, and optimization, resulting in the final EVM bytecode that is stored on the Ethereum network. The steps of the Solidity compilation process are susceptible to manipulation, and an advanced adversary can exploit them for personal gain.
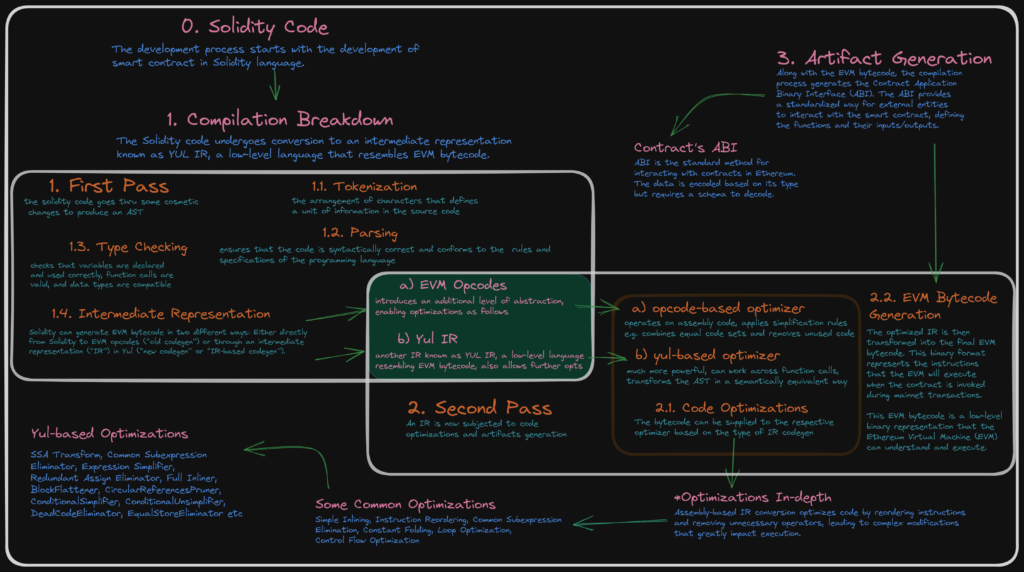
Compilation Breakdown
Solidity code goes through two main passes during compilation: the first and second phases.
1. First Pass Compilation
The first pass of the compilation process involves the following steps:
1.1 Lexical Analysis/ Tokenization
During the first phase of compilation, which is lexical analysis, the Solidity code is tokenized, broken down into a series of tokens (the arrangement of characters that defines a unit of information in the source code), which includes individual words, symbols, and operators. This step helps identify the fundamental elements of the code as defined in the Solidity Lexer.
1.2 Syntax Analysis/ Parsing
The tokens are parsed to generate an Abstract Syntax Tree (AST), representing the structure of the Solidity code in a hierarchical manner. This step ensures that the code is syntactically correct and conforms to the rules and specifications of the Solidity programming language defined in the Solidity Parser. The steps involved are; noting syntax errors, helping in building a parse tree, acquiring tokens from the lexical analyzer, and scanning for syntax errors, if any.
1.3 Semantic Analysis/ Type Checking
The AST is subjected to type checking, where the compiler verifies that the code follows the type rules defined by Solidity. It checks that variables are declared and used correctly, function calls are valid, and data types are compatible. Type checking helps identify type-related errors and ensures type safety within the code.
1.4 Intermediate Representation
Solidity can generate EVM bytecode in two different ways: Either directly from Solidity to EVM opcodes (“old codegen”) or through an intermediate representation (“IR”) in Yul (“new codegen” or “IR-based codegen”).
- EVM Opcode
At this point, the AST is subjected to one of the two intermediate representations, called assembly-based IR, aka EVM opcodes. This stage introduces an additional level of abstraction, enabling optimizations based on the rules defined below in the optimization cycle defined in section 2.1.a. below. - YUL IR
The Solidity code’s AST can also be converted to an intermediate representation known as YUL IR, a low-level language resembling EVM bytecode. This allows further optimization, using the Yul IR’s LLVM-based optimizer, as the Solidity code is transformed into a structured format.
2. Second Pass Compilation
The second pass of the compilation process involves code optimization and artifacts generation.
2.1 Code Optimizations
The bytecode can be supplied to the respective optimizer based on the type of IR codegen, either the EVM opcode or the Yul IR codegen. The “old” optimizer operates at the opcode level and the “new” optimizer operates on the Yul IR code.
- The opcode-based optimizer
This module operating on assembly code applies a set of simplification rules. It also combines equal code sets and removes unused code. The old optimizer performed some basic optimizations, which are set by default in the versions of solidity language; however, for extra optimizations like - The Yul-based optimizer
This module is much more powerful because it can work across function calls. It consists of several stages and components (such as SSA Transform, Common Subexpression Eliminator, Expression Simplifier, Redundant Assign Eliminator, and Full Inliner) that all transform the AST in a semantically equivalent way with the goal of ending up either with shorter or at least marginally longer code that will allow further optimization steps.
Some of the common compiler optimizations utilized by both modules are discussed below.
Common compiler optimizations
Some of the commonly employed techniques at this stage are:
Instruction Reordering
The order of instructions within the assembly-based IR can be rearranged to optimize the flow of execution and minimize overhead. Think of it like rearranging puzzle pieces to create a smoother path. The compiler aims to reduce redundant computations and minimize memory access by strategically reordering instructions, resulting in faster and more efficient code execution. Common Subexpression Elimination
This optimization technique identifies repetitive subexpressions within the code and replaces them with a single calculation, eliminating redundant computations. Think of it as simplifying equations. By reducing the number of repeated operations, the compiler minimizes execution time and improves the overall efficiency of the code.
Constant Folding
Constant folding involves evaluating and simplifying expressions that involve only constants at compile time. Think of it as simplifying mathematical equations with known values. The compiler eliminated the need for runtime calculations by precomputing constant expressions, leading to faster execution and reduced computational overhead.
Loop Optimization
Loops play a critical role in many smart contracts, and optimizing their performance is crucial. The further optimization stage applies loop-related techniques such as loop unrolling, loop fusion, and loop-invariant code motion. These techniques aim to reduce loop overhead, minimize branch instructions, and optimize memory access patterns for improved performance.
Loop fusion is a gas optimization pattern that comes highly recommended, but it is currently not a built-in feature of Solidity.
Control Flow Optimization
The compiler analyzes the code’s control flow and applies transformations to optimize branch instructions and minimize conditional checks. Techniques like branch prediction, jump threading, and loop inversion are used to streamline the control flow and reduce the number of unnecessary branches. Think of it as optimizing a roadmap for efficient travel that results in faster and more efficient execution.
2.2. EVM Bytecode Generation
Once the IR is optimized, either assembly-based (EVM opcode) or Yul IR-based, it is transformed into the final EVM bytecode. The EVM bytecode is a low-level binary representation that the Ethereum Virtual Machine (EVM) can understand and execute. It consists of instructions and data representing the smart contract’s behavior and logic.
[icon name="file-alt" prefix="fas"] What happens once the solidity code is finally converted into its final form of EVM Bytecode will be covered in the article series and in-depth in the Smart Contract Security Auditing 401 by BlockApex.
Let's remember for now that until the smart contract is deployed, the attack windows are shaded. This means that a malicious actor cannot view the contents of a legitimate protocol.
However, the tables turn once the EVM bytecode is formed and the smart contract goes live.
3. Artifacts Generation
Along with the EVM bytecode, the compilation process also generates the Contract Application Binary Interface (ABI). The ABI provides a standardized way for external entities to interact with the smart contract, defining the functions and their inputs/outputs.
Enter the Dark Forest
Solidity code is part of a larger system, i.e., the blockchain. Blockchains are of adversarial nature; participants can engage in strategic and competitive actions to gain advantages or exploit vulnerabilities.
For instance, participants can observe pending transactions and choose to exploit this information by engaging in front-running or sniping activities, attempting to execute their own transactions ahead of others.
It’s important to note that the components of the blockchain system can be manipulated if individuals possess advanced and appropriate knowledge to do so.
Let’s look at a blockchain’s components and how they may be manipulated.
1. Consensus Algorithm
Malicious actors can exploit vulnerabilities in the consensus algorithm to gain control over the network or disrupt the consensus process via various types of attacks such as 51% attacks, selfish mining attacks, double-spending attacks, etc.
2. Transaction Pool
Manipulating the transaction pool can involve prioritizing certain transactions over others or spamming the pool with invalid or malicious transactions by
- submitting a high gas tx to push other txs out of the pool
submitting spam txs to increase the size of the pool in order to slow down the tx processing
3. Block Creation
Malicious actors can manipulate block creation by creating invalid blocks or withholding valid blocks to perform selfish mining attacks

4. Smart Contract Execution
Smart Contracts are prone to vulnerabilities in code and logic. Or the execution environment can be tested to perform attacks such as reentrancy attacks or integer overflow attacks, which can lead to unauthorized access, financial losses, or unintended consequences.

5. Forking
Forking can have ill intentions, such as performing double-spending attacks, altering transaction history, or manipulating the consensus algorithm.

6. Network Protocol
Network protocols can have various types of attacks, such as Sybil attacks, eclipse attacks, and routing attacks.

7. Node Software
Vulnerabilities in the node software can be exploited to perform various types of attacks, such as denial-of-service attacks or remote code execution attacks.

8. Miner Extractable Value (MEV)
Miner Extracted Value (MEV) is performed at the expense of other users via Uncle-bandit attacks, time-bandit attacks, sandwich attacks, or frontrunning and backrunning attack.

9. Governance Mechanisms
Malicious actors can exploit governance mechanisms to introduce malicious changes, manipulate decision-making processes, and control the network for personal gain.

[icon name=”times” prefix=”fas”] In the adversarial ecosystem of Blockchain, each interaction stage has seen several exploits over the span of time. These attack windows can be made vulnerable by an actor having a higher knowledge set. For a blockchain security researcher, it is vital that these stages are never hidden from one’s PoV.
Smart Contracts Hold Valuable Data
If you’re following the blog by now, you must be quite familiar with the idea of smart contracts.
Smart contracts hold valuable data. The term “valuable data” refers to information that has inherent worth, whether it is in the form of financial assets, digital assets, intellectual property, personal information, or any other type of data that holds value to individuals or organizations.
The valuable information that smart contract hold includes, but not limited to, are Tokenized assets, financial information, digital property, intellectual property, personal and identity data, supply chain and logistics data, and data marketplaces.
Why protect smart contracts from the start?
We are aware that smart contracts have the primary purpose of executing agreements and removing intermediaries; they are immutable, and most importantly, they hold valuable data. Yet they are written and designed by humans. People like you and me are very much capable of making mistakes, so a need arises that the development of such crucial components of the blockchain ecosystem is made secure by design.
Why is that? A couple of key reasons that prove effective are as follows.
Immutability of Deployment: Once a smart contract is deployed on the blockchain, the code is essentially immutable. Therefore, ensuring the contract’s security before deployment is crucial to mitigate any potential risks.
Permissionless Nature of Interaction: Smart contracts operate in a permissionless environment; this means that adversaries and potential attackers also have unrestricted access to the contract’s code.
Considering the above factors, malicious actors can scrutinize the contract for vulnerabilities, attempt to exploit weaknesses, or launch attacks to extract rewards or disrupt the contract’s functionality. It is essential to proactively secure the contract to protect it from such adversarial actions.
We hereby conclude that developers are responsible for making their smart contracts secure by default, and therefore, they must take measures to identify and address potential security risks during development.
In a nut shell (TL;DR)
Blockchain technology offers more than just decentralization and addresses the limitations of centralized systems. Smart contracts, which are pieces of code stored on the blockchain, automate and execute agreements without the need for intermediaries. They provide efficiency, security, and transparency. However, smart contracts and the components of the blockchain ecosystem are prone to manipulation and vulnerabilities at the finer steps of their execution.
Smart contract auditing is crucial to identify and address these vulnerabilities, ensuring the security of valuable data held within smart contracts. Auditing helps developers protect user funds, maintain contract integrity, and foster trust in the blockchain ecosystem. Thorough security audits and best practices during development are essential to make smart contracts secure by default and prevent the challenges of fixing bugs once deployed on the immutable blockchain.
Read More:
Infiltrating the EVM-II: Inside the War Room’s Arsenal
Infiltrating the EVM-III: Unravel the Impact Of Blockchain On Bug Fixing!
Infiltrating The EVM IV – Echoes of the Past, Visions for Tomorrow