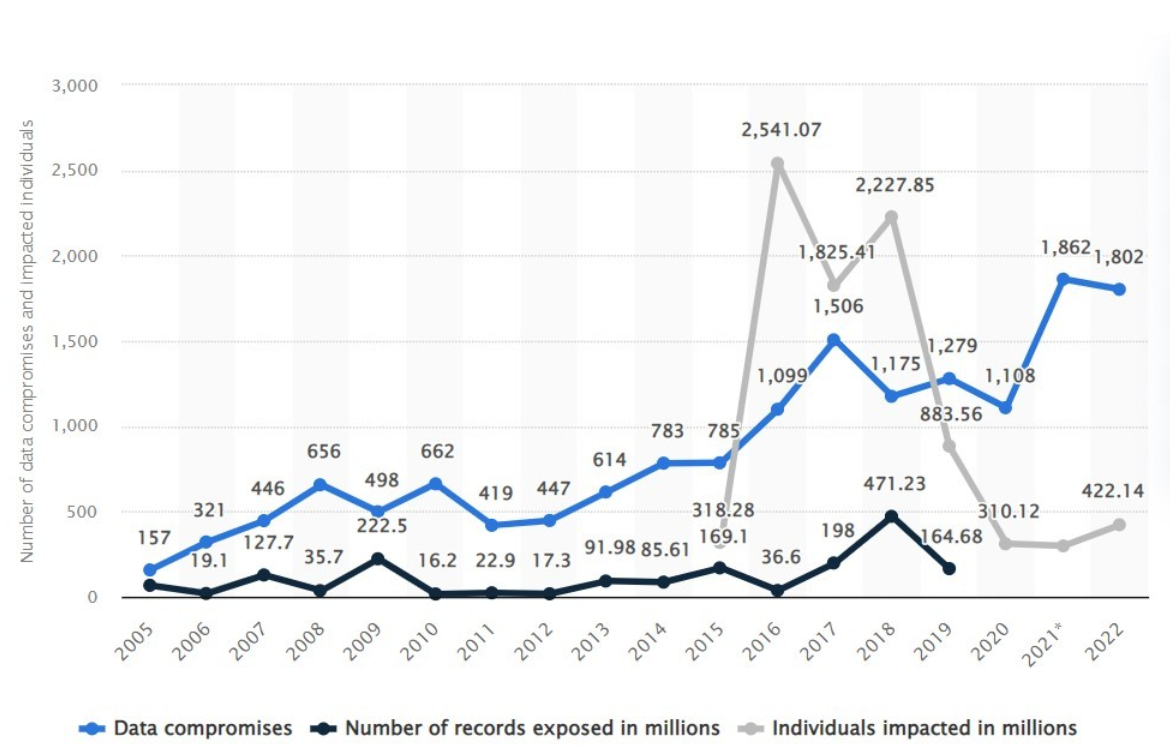
With the ever-increasing digitization, the possibility of data breaches and cyber attacks are also increasing. In these attacks, organizations risk capital loss, customer trust, compliance penalties, and legal costs. With high value at stake, it is essential to figure out how to protect our sensitive data from prying adversaries. As per statista.com, the annual number of data breaches only in the United States in 2022 was 1802 impacting 422 million individuals.
To achieve this, we have techniques like data masking and tokenization. These techniques help us to hide the real details and prevent data breaches from those with unauthorized access while keeping data usable. Each of these techniques has its own use and serve a particular purpose to ensure that our data remains secure. In this blog post we will see the individual definition of data masking and tokenization and what are the differences between the two. We will also look into their use cases. Let’s start with data masking.
What is Data Masking?
Data masking conceals sensitive information of our data source by modifying the data with fictitious data. A representation of the original data with similar structure is used in place of original data. We modify the data in a way that it has no value to unauthorized intruders or malicious insiders, however, the system can still use this data for its own purposes.
Data masking is primarily implemented in two ways: Static Data Masking (SDM) and Dynamic Data Masking (DDM). Both of them are essential for securing sensitive information tailored to different scenarios and use cases.
-
Static data masking
Static Data Masking (SDM) is a strategy designed for the use of non-production environments. In it, we replace the important data with sanitized copies of data in a way that the structure of data retains. The masked data withholds its essential properties and format but removes any identifiable or sensitive information, thus maintaining data utility while enhancing security. For example, in a healthcare database, patient names and social security numbers might be replaced with randomly generated equivalents that still look realistic but do not expose any actual patient information. This allows developers or testers to use the database without risking a data breach or violating privacy regulations.
-
Dynamic data masking
Dynamic data masking (DDM) on the other hand, is a security feature that conceals sensitive data in real-time to protect it from unauthorized access. It allows legitimate users to interact with the data without compromising its integrity unlike static data masking, which permanently alters a copy of the data, dynamic data masking hides or obscures data dynamically based on user roles or permissions. This approach ensures that sensitive information, such as credit card numbers or social security numbers, is only visible to authorized personnel, while other users see a masked version, such as a series of asterisks or a partial display of the data.
For example, in a customer service application, a support agent might only see the last four digits of a customer’s credit card number, while the full number remains hidden. This approach allows organizations to maintain data security and privacy compliance while still providing access to the data necessary for daily operations.
Use Cases of Data Masking
So when do organizations prefer using data masking?
By far the most common use case for data masking is where data privacy is important while allowing developers to perform normal operations with obfuscated data. Information like social security numbers, credit card numbers, or personally identifiable information are mapped with preserved properties. This will enable the developers of the system to test, develop, or QA teams to carry out their normal operations without revealing the sensitive data.
Also Read: Credit Card Tokenization Explained
Challenges of Data Masking
While data masking is useful, it has its own limitations. For example, inaccurate or poorly masked data can lead to unreliable testing results or flawed insights, potentially undermining business decisions. Additionally, ensuring comprehensive coverage is difficult, as data masking must account for all locations of sensitive data across databases, applications, and even backups. This complexity can make the process resource-intensive and time-consuming. This will also require constant monitoring and updates to mask newly identified sensitive data or adapt to changing regulations.
What is Tokenization?
Tokenization is the process of replacing sensitive data elements with randomly generated data strings known as “tokens.” These tokens interact within the system’s databases as representatives of the original data set. The token itself has no exploitable value or meaning outside of the secure environment where it is mapped to the original data. Thereby it reduces the risk of data breaches and unauthorized access.
For example, in a payment processing system, a customer’s credit card number might be tokenized into a random string like “F4E5A8B1.” This token is used during transactions instead of the actual card number, ensuring that even if the data is intercepted or stolen, it cannot be used to make fraudulent transactions. The original credit card number is securely stored in a separate token vault, accessible only by authorized systems, maintaining data security without disrupting business operations.
Also Read: What is Data Tokenization?
Difference between Tokenization and Data Masking
The main difference between data masking and tokenization is that tokenization is reversible. It is intended for use cases where the original data needs to be securely restored, like in payment systems. For example, a restaurant keeps a token instead of your credit card number on file for payments.
However, in data masking the original data is permanently altered or masked, and cannot be reversed or retrieved back to its original form. For example, a bank creates a masked version of its customer database for testing software without risking real customer information exposure.
Challenges of Tokenization
While tokenization is best suited for payment systems to hide sensitive information. It has its own technical challenges. In general tokenization requires a specific infrastructure for implementation which may cause the slow down of processes due to the potential overhead of tokenization and de-tokenization. Additionally, if an attacker gains access to the tokenization system, tokens can be exchanged back into the original value.
Also Read: What is Payment Tokenization?
Comparison of Data Masking and Tokenization
Choosing between data masking and tokenization depends on one’s specific need and use case. If an organization needs to preserve both the privacy and the utility of its data, while granting access to software development, customer success, and sales teams, data masking is likely the better choice.
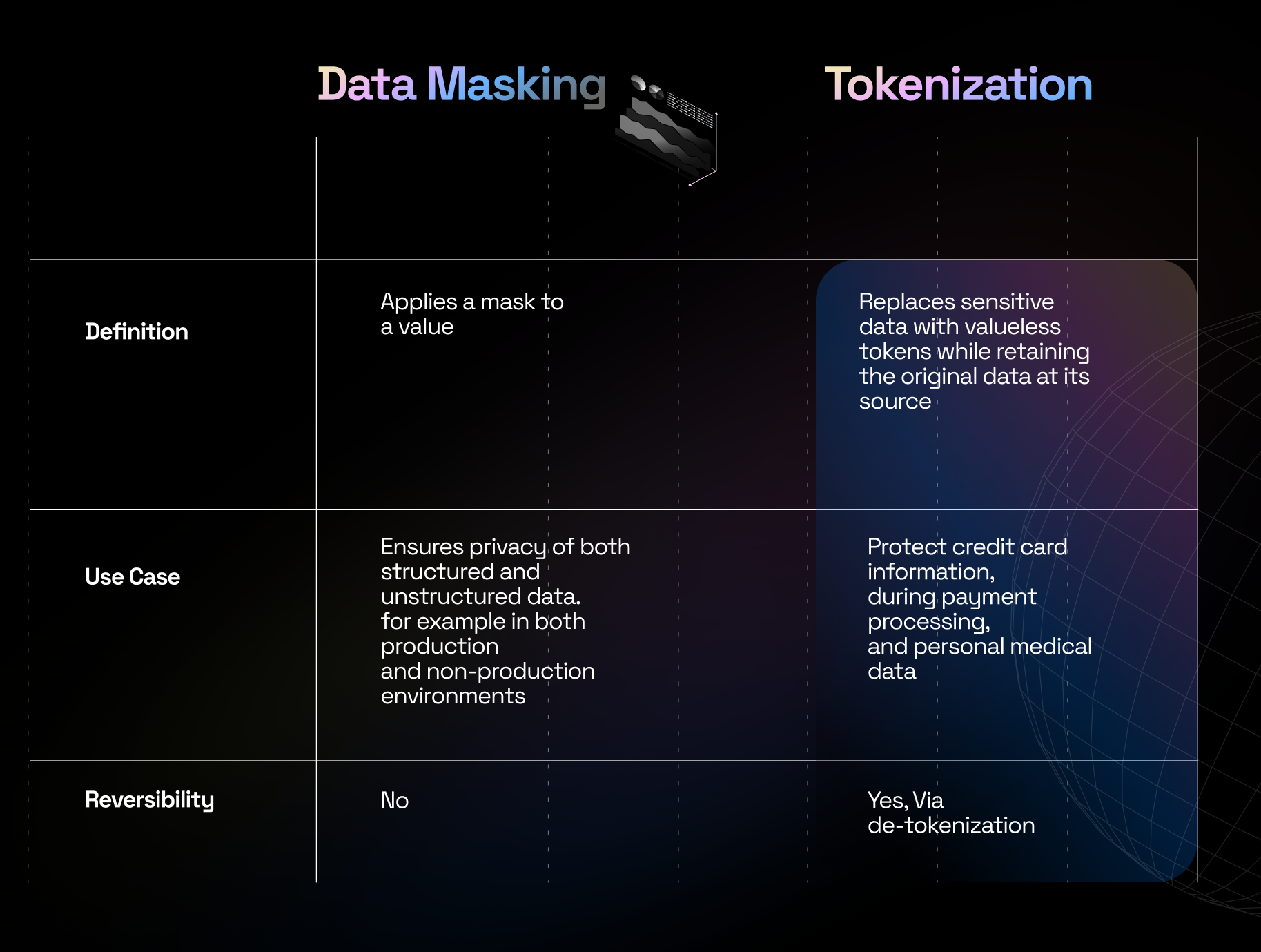
On the other hand, if an organization needs to protect sensitive data while allowing authorized users to access and process the protected data for use in analytics, tokenization may be a better choice.
Performance
Data masking is comparatively faster than tokenization as it handles data locally, on the same database. While tokenization is a bit slower because it requires the token to be linked to a token vault which is stored elsewhere.
Integrity
Tokenization can preserve data relationships more effectively than data masking. Each unique sensitive data element corresponds to a unique token. These tokens simply point to the original stored data and hence no alteration of data can be found. Data masking, on the other hand, maps the data to another value and hence can not guarantee the integrity of data.
Scope
The scope of each technique depends on their use case. Tokenization is better suited for structured data, especially when dealing with structured sensitive data. Conversely, data masking can handle large data of both structured and unstructured types.
Conclusion
Protecting your organization’s sensitive data requires the right balance between security, compliance, and usability. Data masking and tokenization both offer solid solutions but fit different needs. To make the right choice, assess how your data is used, its sensitivity, and compliance requirements.
Need help deciding? Reach out to BlockApex, and we’ll guide you toward the best data security strategy for your business.