The security of most cryptographic systems cannot currently be proved unconditionally, and must be proved under the assumption that a certain computational task is difficult. In the previous edition of the Zero-Knowledge cryptography series, we thoroughly explored the fundamentals of our first computational problem. This was done via DLP with its application in the Elliptic curve for higher security guarantees in Zero-Knowledge proofs. Next we will jump into our last two primitives which are Knowledge of exponent and group of unknown orders. These are mainly leveraged by RSA and Discrete log problem. In this post on zero-knowledge, I will try to comprehensively explain the KoE assumption. Next in the series we will learn about our last primitive, Group of Unknown orders.
Read the previous blog post on a primer for zero-knowledge cryptography from here.
The Knowledge of Exponent Assumption(KoE)
Background
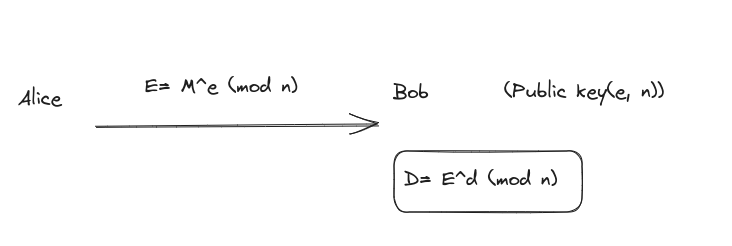
Knowledge of Exponent (KoE) is a cryptographic concept that involves demonstrating knowledge of the exponent in a given equation without revealing the actual exponent itself. It’s often used in various cryptographic protocols to prove possession of a private key without disclosing the key itself.
For example, in public-key cryptography, you might encrypt a message using the recipient’s public key (e, n) by raising it to a specific exponent modulo a modulus:
E = (\text{Message})^e \mod n
The recipient can then decrypt the message using their private key D=Ed mod n.
The concept of Knowledge of Exponent (KoE) aligns closely with the principles of zero-knowledge proofs. Zero-knowledge proofs allow one party (the prover) to convince another party (the verifier) that a statement is true without revealing any information beyond the validity of the statement itself. In the context of KoE, this means proving possession of the exponent in a given equation without divulging the actual value of the exponent.
Definition
This assumption was first proposed by Ivan Damgård in his paper which says:
“If an algorithm, given the description of finite group along with some other public information, computes a list of group elements that satisfies a certain algebraic relation, then there exists a knowledge extractor that outputs some related values that “explain” how the public information was put together to satisfy the relation.”
In other words, given g, gα in a group G it is infeasible to create c, c^ such that c^= cα without knowing where, c=gα and c^=(gα)α.

Now, I understand that the above statement seems like little jargon to y’all. To tell you the truth, when I was reading about this topic, I found no resources available except a few research papers and complicated videos. For this very reason, I will try to explain this topic as simply as I can. The reason being, this is the most widely used primitive in multiple polynomial commitment schemes such as KZG in Plonk.
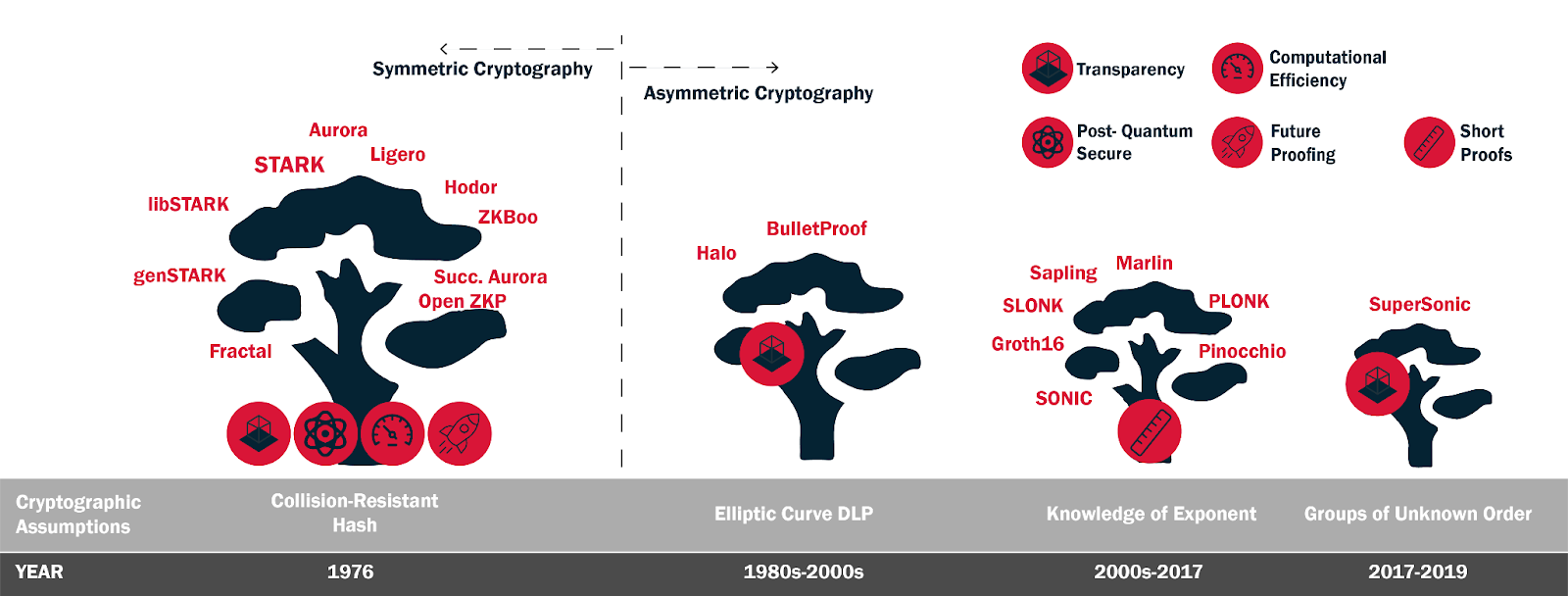
Explanation
The knowledge of exponent assumption is a generalization of KoE. It says that
given the successive powers of some random value s ∈ Zp encoded in the exponent {g, gs, gs2, . . ., gsα, gα,gsα, . . . gαs q}, It is infeasible to create c, c^ where c^= cα.
\{ g, gs, gs^2, \ldots, gs^{(u-1)}, g, gs, \ldots, gs^q \}
Without knowing 0, 1, . . . q that satisfies the relation:
C = \prod_{i=0}^{q} \left( \frac{s}{g} \right)^{\alpha_i}
In simple words, if an adversary is provided with some group knowledge and public parameters(statement being proven). Then, there is no way that the adversary could find the secret values that have been mapped in that group. These assumptions can be reformulated in terms of encodings, as a generalization of the exponential function in the bilinear group which we will discuss in our future series on encoding and commitment schemes. But for a general idea of how and where exactly in our proof system we need KoE assumption. Let’s consider a rough scenario where a prover alice commits to some polynomial f(τ) and publishes it to the blockchain.
Now any verifier or lightnode on the network wants to check that Bob has really committed to some original polynomial and not to some random data. Now this is hard to check. Because by looking at the commitment you can’t simply verify the mathematical relation behind it.
Example
To understand it in a comprehensive way, we need to build a simple snark protocol for your understanding. We have a prover, Bob who possess the knowledge of a polynomial with degree 3 which is:
x^3 - 3x^2 + 2x = (x - 0)(x - 1)(x - 2)
Now this Bob claims that he knows a polynomial of degree 3 with the roots 1 and
2, this means that his polynomial has the form:
(x-1)(x-2). . . .
In other words (x − 1) and (x − 2) are the cofactors of the polynomial in question. Hence if Bob wants to prove that indeed his polynomial has those roots without disclosing the polynomial itself. He needs to prove that his polynomial p(x) is the multiplication of those cofactors t(x) = (x − 1)(x − 2), called target polynomial, and some arbitrary polynomial h(x) (equals to x − 0 in our example).
Using polynomial identity check protocol we can compare polynomials p(x) = t(x)·h(x):
- Alice is a verifier who samples a random value r, calculates t = t(r) and gives r to the prover. For instance he samples a random value 23. Then, calculates t = t(23) = (23 − 1)(23 − 2) = 462 and gives 23 to Bob.
- Bob calculates h(x)=p(x)t(x) and evaluates p(r) and h(r); the resulting values p, h are provided to the verifier. For example, in our example he evaluates p = p(23) = 10626 and h = h(23) = 23. Then, he provides p, h to Alice.
- Alice then checks that p = t · h= 10626 = 462 · 23, which is true. Therefore, it proves the statement.
Now we can check a polynomial for specific properties without learning the polynomial itself. This already gives us some form of zero-knowledge and succinctness. Nonetheless,
there are multiple issues with this construction:
- Bob may not know the claimed polynomial p(x) at all. He can calculate evaluation
t = t(r), select a random number h and set p = t· h. The verifier will accept this as valid, since the equation holds.
- Because alice has provided the random value(r) to Bob without any encryption. So now, bob knows the random point x = r, he can construct any polynomial which has one shared point at r with t(r) · h(r).
The is one other important thing to note here. In the original statement, Bob claims to know a polynomial of a particular degree; in the current protocol there is no enforcement of degree. Hence the prover can cheat by using a polynomial of higher degree which also satisfies the cofactors check.
Now here, you might argue that if we give a user an encrypted random value, then the prover will have to use homomorphic encryption for the evaluation of the polynomial. He might not be able to cheat us. If you do, then you are right 😀
So now we will modify our snark protocol a bit. Let us see how we can evaluate a polynomial
p(x) = x^3 - 3x^2 + x
As we have established previously to know a polynomial is to know its coefficients or roots. In this case those are: 1, -3, 2. Because homomorphic encryption does not allows to exponentiate an encrypted value. We must have been given encrypted values of powers of x from 1 to 3:E(x), E(x2), E(x3). Why? so that we can evaluate the encrypted polynomial as follows:
E(x^3) = 1 \cdot E(x^2) - 3, \quad E(x) = 2 \\ (g^3) = 1 \cdot (g^2) - 3 \cdot (g^1) + 2 \\ g \cdot x^3 - 3x^2 + 2x
As the result of such operations, we have an encrypted evaluation of our polynomial at some unknown to us x. This is quite a powerful mechanism, and because of the homomorphic property, the encrypted evaluations of the same polynomials are always the same in encrypted Space. We can now update the previous version of the protocol, for a polynomial of degree.
Verifier
- Alice samples a random value secretly i.e s.
- Calculates encryption of s for all powers i in 0, 1, …. D. i.e, E(si)=gs^i.
- Evaluates unencrypted target polynomial with s: t(s).
- Encrypted powers of s are provided to the prover E(s0), E(s1), . . .E(sd) along with t(s) without disclosing any knowledge about secret s.
Note: Alice does not know the coefficients of polynomials i.e, 1, -3, 2 however, she knows about the degree of polynomial.
Prover
- Bob calculates polynomial h(x)=p(x)/t(x).
- Using encrypted powers E(s0), E(s1), . . .E(sd) and coefficients c0, c1, . . .cd, evaluates E(p(s))=gp(s)=(gsd)cd. . . .(gs1)c1(gs0)c0 and similarly E(h(s))=gh(s) by simply dividing the E(p(s)) to t(s).
- The resulting gp and gh are provided to Alice.
Verifier
- For Alice, the last step is to check the relation p=t(s).h or in encrypted space gp=(gh)t(s) gp=gt(s).h.
So because the prover does not know anything about s, it makes it hard to come up with non-legitimate but still matching evaluations. In such a protocol, the prover cannot forge a proof. However, he still can cheat without actually using the provided encryptions of powers of s.
For example, the prover can commit to some other polynomial of degree less than 2 say s3 and s1 and still be able to make correct evaluations. This is because we have only restricted the verifier to use the input provided by verifier in an encrypted way. We still need to make sure that the prover is using the right polynomial for the evaluation of encrypted input data. Let’s try to comprehend how?
Restriction of Polynomial
The knowledge of each polynomial lies in its coefficients c0, c1, c2, . . ci. We assign those coefficients through exponentiation of the corresponding encrypted powers of the secret values s. Though we have restricted the prover to use the encrypted evaluations provided by verifier. However, the prover can still cheat by using some random arbitrary values zp, zh which satisfy equation zp=(zh)t(s) and provide them to verifier instead of correct gp and gh.
zh=gr and zp=(gt(s))r, where gt(s) can be computed from provided encrypted power of s. . That is why verifier needs the proof that only supplied encryptions of powers of s were used to calculate gp and gh and nothing else.
To give you an example, consider an example of a degree 1 polynomial with one variable and one coefficient, f(x)=c.x and correspondingly the encryption of s is provided E(s)=gs. We are looking to ensure that only the encryption of s was homomorphically multiplied by some arbitrary coefficient c. We can achieve this through the KoE assumption introduced in Dam91.
Protocol Working
Suppose Alice is a verifier and she has a value that she wants to get exponentiated by some power. The single requirement is that only this a can be exponentiated and nothing else, to ensure that we follow a specific protocol:
- Alice Choose a random.
- Calculates a= aαmod n
- Provides the tuple (a, a–) to bob and ask to perform some arbitrary exponentiation of each value and reply with the resulting tuple (b, b–) where the α – shift remains the constant i.e bα=b– mod n
Because Bob cannot extract α from the tuple (a, a ) other than through a brute-force which is infeasible, it is must that the only way Bob can produce a valid response is through the procedure.
- Chose some value c
- Calculate b=(a)c mod n and b—=(a–)c mod n
- Reply with (b, b–)
Having the response and alice checks the following equality:
\begin{align*}
-(b)^\alpha &= \overline{b} \\
-(a)^\alpha_c &= (\overline{a})^c \\
a^{\overline{c}\alpha} &= (\overline{a})^c
\end{align*}
So this way Bob has applied the same exponent (i.e., c) to both values of the tuple and he could only use the original Alice’s tuple to maintain the α relationship. Bob knows the applied exponent c, because the only way to produce valid (b, b) is to use the same exponent. Alice also has not learned c for the same reason Bob cannot learn α. This is how we have achieved soundness using the KoE assumption.
Why KoE over DLP?
The DLP assumption relates to the difficulty of solving the discrete logarithm problem. This involves finding an exponent given a base and a result(we have discussed this in part II of this series). In contrast, the KoE assumption deals with proving knowledge of an exponent used in a public-key encryption scheme without revealing the exponent itself. Plonk and Halo both are cryptographic proof systems, but they differ in their underlying cryptographic assumptions and approaches. Plonk relies on knowledge of exponentiation, which involves efficient exponentiation operations. This choice makes Plonk suitable for applications that require quick proof generation and verification due to its computational efficiency.
Halo, on the other hand, relies on the discrete logarithm problem, which is a widely studied problem in cryptography. However, The use of discrete logarithms in Halo can be computationally intensive, especially for larger groups or prime fields because of the double and add method. This may impact the efficiency of proof generation and verification, potentially making it less suitable for high-throughput applications.
Connection with Zero-Knowledge
In the realm of cryptographic protocols, the concept of Knowledge of Exponent (KoE) aligns closely with principles of zero-knowledge proofs. Zero-knowledge proofs enable one party (the prover) to convince another party (the verifier) of a statement’s truth without revealing any information beyond the validity of the statement itself. Applied to KoE, this means proving possession of the exponent in a given equation without disclosing the actual value of the exponent, thereby preserving privacy and security.
In simple words, if an adversary is provided with some group knowledge and public parameters (the statement being proven), there is no way for the adversary to determine the secret values that have been mapped in that group, thereby upholding the principles of zero-knowledge.