Introduction to ICP Canisters Security Audit
The Internet Computer Protocol (ICP) is a third-generation blockchain that offers decentralized computation and scalable storage, enabling smart contracts, or “ICP canisters,” to operate with near-native performance. These canisters combine code and state, allowing developers to build highly scalable and interoperable Web3 services. However, while ICP opens new avenues for scalable and robust decentralized applications (dApps), it also brings unique security challenges. Securing ICP canisters is critical to ensure applications operate as intended, safeguarding them from potential vulnerabilities and malicious attacks.
ICP canister security goes beyond merely preventing unauthorized access or asset theft; it encompasses the correct execution of smart contracts per project specifications and user expectations. With its unique architecture—including inter-canister communication, asynchronous execution, and efficient resource management—ICP canisters introduce specific attack vectors that developers must be aware of and address proactively.
This article provides a comprehensive introduction to ICP canister security by exploring the mindset of potential attackers, identifying vulnerabilities within the canister ecosystem, and offering strategies for securing ICP canisters effectively. This is just the start of our deep dive into ICP canister security. Upcoming guides will cover additional attack vectors, best practices for securing ICP canisters, and advanced defensive techniques to fortify your Web3 projects on the Internet Computer.
Note: This article is for readers with an understanding of canister development on the Internet Computer (ICP) and its architecture. We won’t cover the basics of building canisters or explain general ICP concepts. Instead, we’ll focus on the key security aspects of canisters. If you’re new to ICP, we recommend checking out the official ICP documentation. We will also share insights from our recent audit (Meta Pool ICP Audit) of an ICP canister, highlighting the security considerations and best practices that emerged during our engagement.
The Attacker Mindset in Exploiting Canisters on the Internet Computer
The Internet Computer’s architecture presents a unique set of challenges and opportunities for attackers looking to exploit canisters, the core computational units on the network. Canisters are designed to manage state, interact with other canisters, and handle cycles (the computational resources on the Internet Computer). An attacker with a deep understanding of these dynamics can find various avenues to disrupt operations or manipulate canisters for malicious purposes.
-
Canister Autonomy and State Management
Canisters on the Internet Computer are autonomous and handle their state. This autonomy, while powerful, introduces potential vulnerabilities. An attacker might exploit weaknesses in state management, particularly in how a canister processes incoming messages or inter-canister calls. If a canister does not rigorously validate incoming data or fails to account for state changes during asynchronous operations, it could be manipulated into performing unintended actions. This could lead to unauthorized data access, state corruption, or even the depletion of a canister’s cycles, effectively rendering it inoperative.
-
Abusing Message Ordering and State Inconsistency
Attackers may exploit the asynchronous message system of ICP by intentionally triggering inter-canister calls that result in unpredictable message ordering. If a canister is not built to handle reentrancy or time-of-check-to-time-of-use (TOCTOU) vulnerabilities, attackers could manipulate race conditions to perform unauthorized actions, such as double-spending tokens or incorrectly calculating balances. Ensuring robust locking mechanisms and state validation post-message processing can mitigate these threats.
-
Resource Exhaustion Through Cycle Management
The “reverse gas model” of the Internet Computer, where canisters pay for their execution in cycles, opens up another attack vector. An attacker can drain a canister’s cycle balance by triggering resource-intensive operations or spamming it with numerous requests. Once depleted, the canister cannot process further requests, leading to a denial of service. Ensuring efficient cycle management and monitoring is crucial to mitigate such attacks.
-
Manipulating Upgrade Processes
Attackers may target the canister’s upgrade process, especially if they can trigger conditions that prevent successful upgrades. A canister that traps during the pre-upgrade or post-upgrade phases becomes vulnerable to being stuck in an unupgradable state. An attacker could inflate data stored in a canister, overwhelming its ability to process an upgrade and causing a denial of future updates. Therefore, it’s critical to stress-test canisters with large data loads and ensure smooth upgrades with minimal data in stable variables.
Secure Canister Development: Key Components and Best Practices
Here are the essential components and best practices for securely developing Motoko-based canisters, addressing common issues and vulnerabilities typically found during audits. These practices also include insights gathered from our recent audits of ICP canisters.
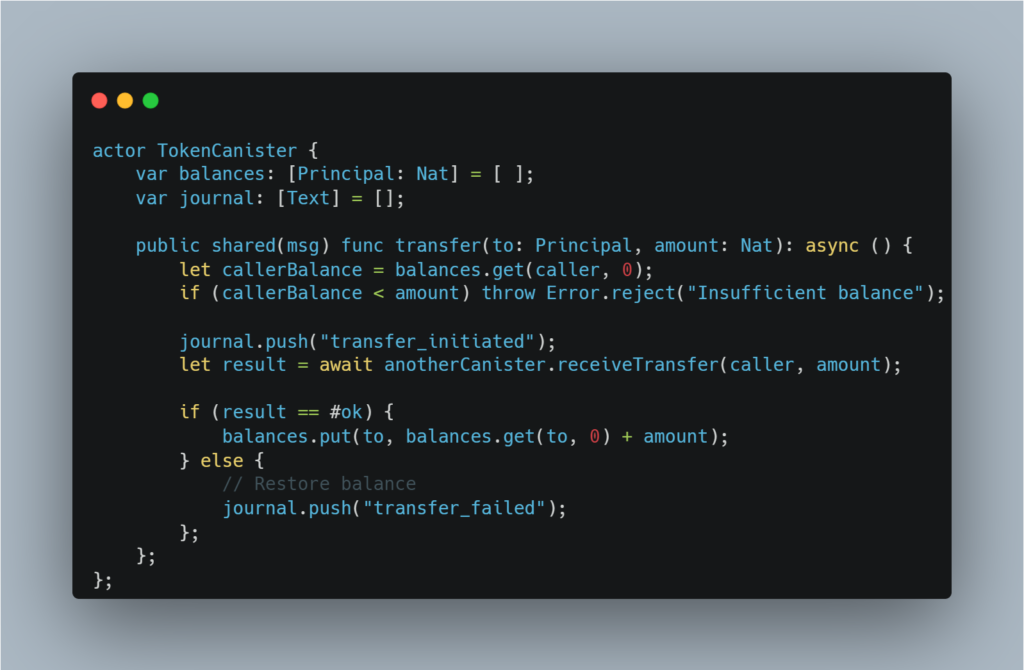
1. Inconsistent State and Traps in Callbacks
Security Concern:
When a canister modifies its state and then makes an asynchronous inter-canister call, there’s a risk that a trap (error) during the callback may leave the canister in an inconsistent state. This can lead to serious vulnerabilities such as incorrect balance calculations or incomplete operations.
Example:
A canister deducts tokens from a sender’s balance and makes an inter-canister call to transfer funds, but traps before completing the callback. If the trap happens, the sender’s balance might not be restored, leading to an inconsistent state.
Mitigation:
Implement journaling. Before any state changes, record the intent to perform an operation. This journal acts as a fallback in case the callback traps. If the operation fails, the journal can help restore the previous state without inconsistencies.
Code Example
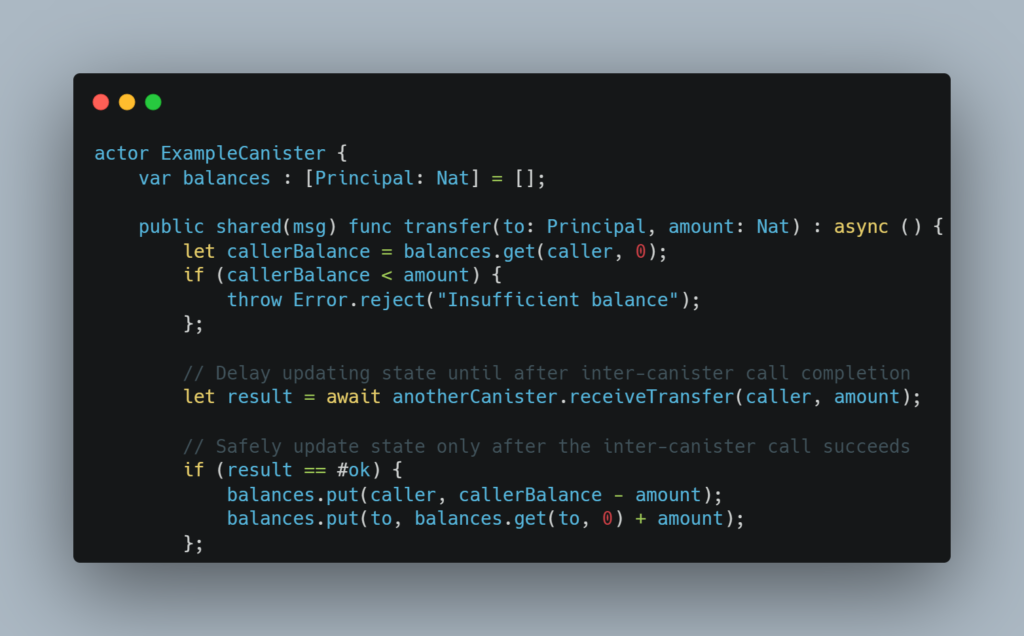
2. Message Ordering and Reentrancy Bugs
Security Concern:
On the Internet Computer (ICP), individual messages are processed atomically, but inter-canister calls do not have guaranteed ordering. This lack of strict ordering can lead to reentrancy bugs, where an attacker can exploit the gap between initiating and completing an inter-canister call to perform unauthorized operations multiple times before the state is updated.
Example:
A canister checks if a user has enough tokens to withdraw, and makes an inter-canister call to transfer the funds, but before the withdrawal completes, the same user submits another withdrawal request. This could cause double spending or incorrect balance updates because the state has not been updated in time.
Mitigation:
To prevent reentrancy bugs, implement locking mechanisms that block multiple operations from modifying the state simultaneously. A per-caller lock or a global lock ensures that only one process can change critical data at a time.
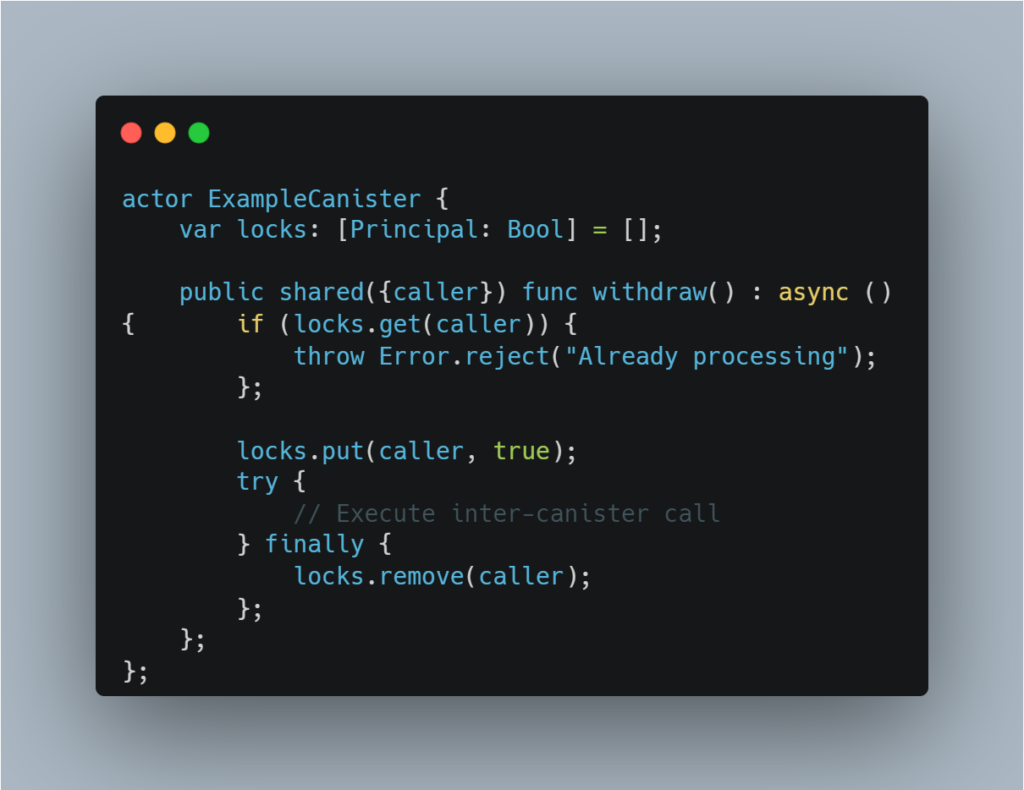
3. Time-of-Check to Time-of-Use (TOCTOU)
Security Concern:
TOCTOU vulnerabilities occur when a condition (like checking a user’s balance) is verified before an inter-canister call is made, but the state of the canister changes before the call completes. This creates a window for attackers to exploit the race condition, causing unexpected behavior like double-spending or overdrafts.
Example:
A canister checks if a user has enough tokens to withdraw, and then initiates an inter-canister call to process the withdrawal. However, before the withdrawal is completed, another process withdraws tokens from the same account. This means that by the time the withdrawal is completed, the user’s balance may be incorrect, potentially causing an overdraft or double withdrawal.
Mitigation:
To prevent TOCTOU vulnerabilities, avoid relying on state checks made before an inter-canister call. Instead, perform critical state updates after the call is completed or within the same atomic block of code to ensure that the state is consistent.
4. Handling Rejects and Failures
Security Concern:
Inter-canister calls can fail due to several reasons, such as insufficient cycles, network issues, or rejection by the target canister. If you don’t properly handle failures, you may end up with false assumptions that the operation succeeded, leading to inconsistencies in the state or incomplete transactions.
Example:
A canister makes a transfer call to another canister. If that call fails but the failure isn’t handled properly, the calling canister may still assume the transfer succeeded, leading to incorrect token balances or other errors.
Mitigation:
Always handle potential failures or rejections in inter-canister calls explicitly. Make sure to check the result of every call, and either roll back or retry operations if they fail. This ensures that no assumptions are made about the success of an operation without proper verification.
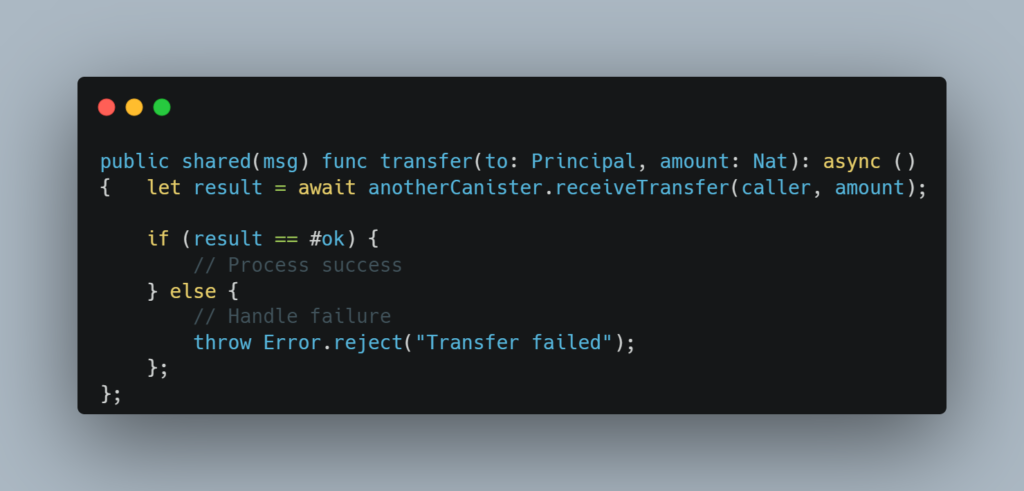
5. Untrusted Canister Calls
Security Concern:
When making inter-canister calls to an untrusted canister, you expose your own canister to risks such as a Denial-of-Service (DoS) attack or receiving incorrect data. An untrusted canister could stall indefinitely, causing your canister to hang while waiting for a response.
Example:
A canister makes a call to an untrusted service that stalls without returning a response. Without precautions, the calling canister would be stuck waiting, leading to a potential DoS scenario.
Mitigation:
Use a state-free proxy canister when dealing with untrusted canisters. The proxy canister acts as an intermediary that can be reinstalled if it becomes unresponsive. This way, if the proxy fails, it can be reset without affecting your main canister’s operations.
6. Avoid Loops in Call Graphs
Security Concern:
When multiple canisters call each other in a loop (e.g., A calls B, B calls C, and C calls A), it can lead to deadlocks—situations where the canisters are waiting for each other indefinitely, effectively halting the system.
Example:
Canister A makes a call to Canister B, which then calls Canister C. If Canister C, in turn, calls back to Canister A, a circular dependency is created. This loop can prevent any of the canisters from completing their operations, causing the system to stall.
Mitigation:
Carefully map out inter-canister call flows to ensure that there are no circular dependencies. By avoiding loops in the call graph, you can prevent deadlocks and ensure that canisters aren’t stuck waiting for each other
7 . Canister Upgradeability
Security Concern:
When a canister traps (fails) during its canister_preupgrade method, it can permanently block the canister from being upgraded, leading to a major risk where the canister becomes non-upgradeable.
Example:
In Motoko, the canister_preupgrade method serializes data into stable memory. If the data exceeds the system’s instruction limit or the size of the stable memory, the canister may trap, preventing further upgrades.
Mitigation:
- Avoid storing large data in stable variables. Instead, store only minimal configuration data in stable vars.
- Load testing: Simulate upgrades with an inflated dataset to ensure your canister can handle the expected load.
- Backup data off-chain: Store non-critical data off-chain and re-hydrate after upgrades.
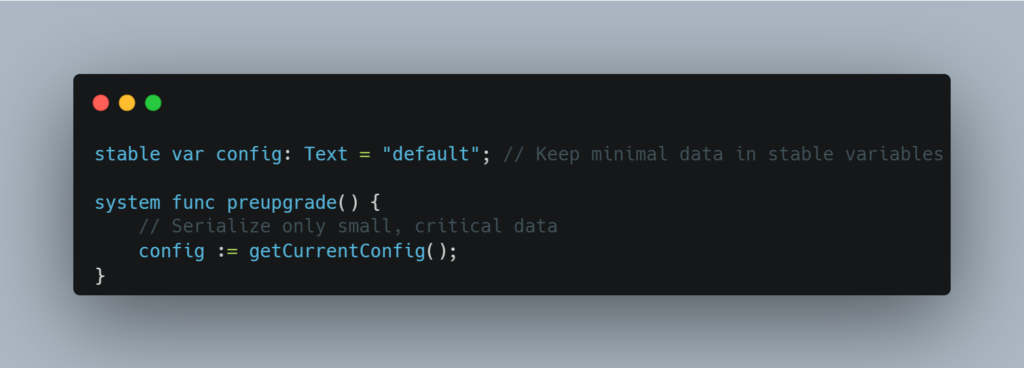
8. Data Retention and Consistency During Upgrades
Security Concern:
During canister upgrades, ensuring that critical data is retained is essential. If non-stable variables (which are not automatically saved across upgrades) are not correctly transferred to stable storage, important information may be lost. This can lead to inconsistencies in the canister’s state or even data loss.
Example:
If a canister has user balances stored in a non-stable variable and doesn’t properly migrate them to a stable variable before upgrading, the user balances will be lost after the upgrade.
Mitigation:
Use stable variables for any data that needs to persist across upgrades. Always implement both pre-upgrade and post-upgrade hooks to ensure that data is properly transferred between stable and non-stable variables.
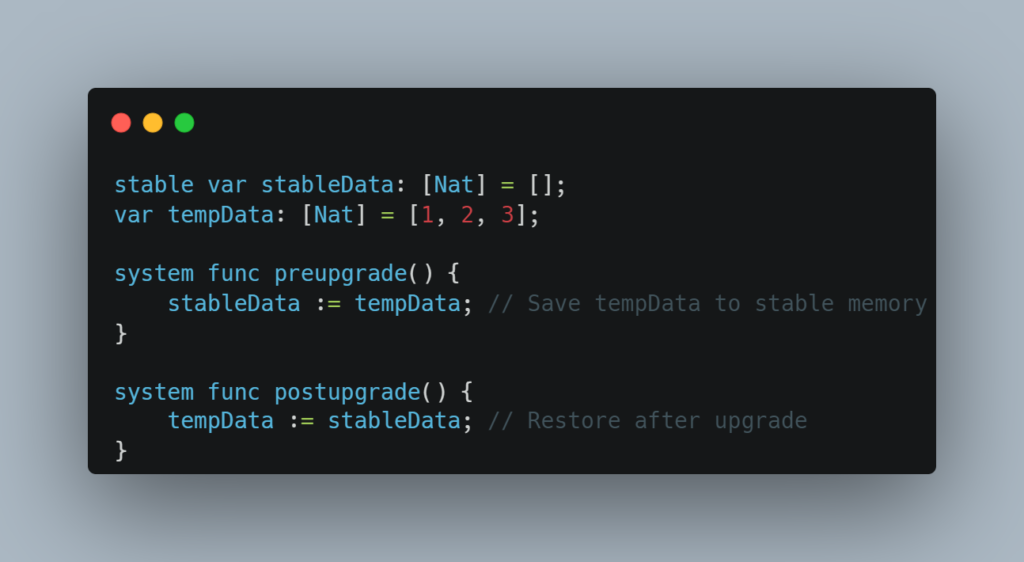
9. Prompt Upgrades and Inter-Canister Calls
Security Concern:
If a canister has pending inter-canister calls, it can delay the upgrade process, potentially exposing the system to security risks, especially when dealing with untrusted canisters that might not respond. Upgrading while waiting for responses from such canisters can cause inconsistencies.
Example:
A canister makes an inter-canister call and waits for a response before upgrading. If the response never arrives, the upgrade may be delayed indefinitely.
Mitigation:
- Stop the canister before upgrading to ensure no pending calls interfere with the process.
- Trustworthy Canister Calls: Avoid making critical inter-canister calls to potentially untrusted canisters.
- Design workflows to minimize dependency on external canisters
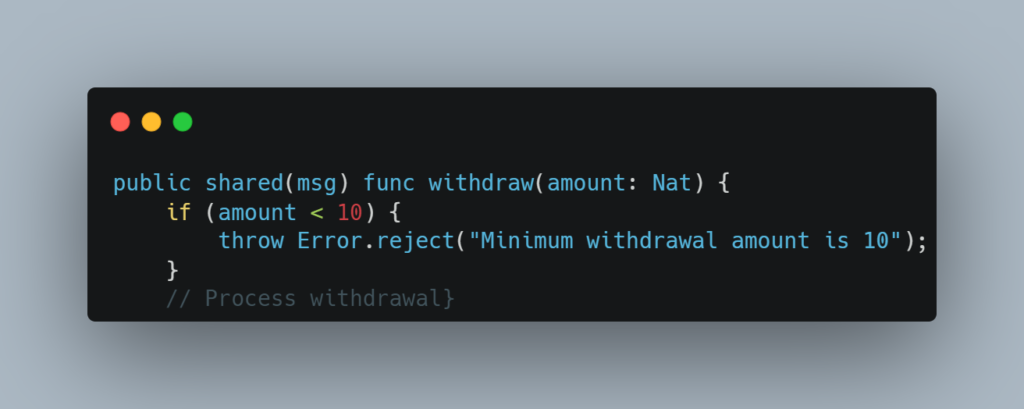
10. Resource Exhaustion
Security Concern:
Excessive operations like frequent withdrawals or referral code generations can lead to resource exhaustion, bloating the canister’s state and draining its cycles. This can lead to Denial of Service (DoS) attacks and complicate upgrades.
Example:
Users could generate numerous referral codes or make many small withdrawals, consuming excessive resources and potentially crashing the canister.
Mitigation:
- Rate Limiting: Implement limits on how frequently users can withdraw or generate referral codes.
- Minimum Withdrawal Amount: Prevent users from executing tiny withdrawals that consume disproportionate resources.
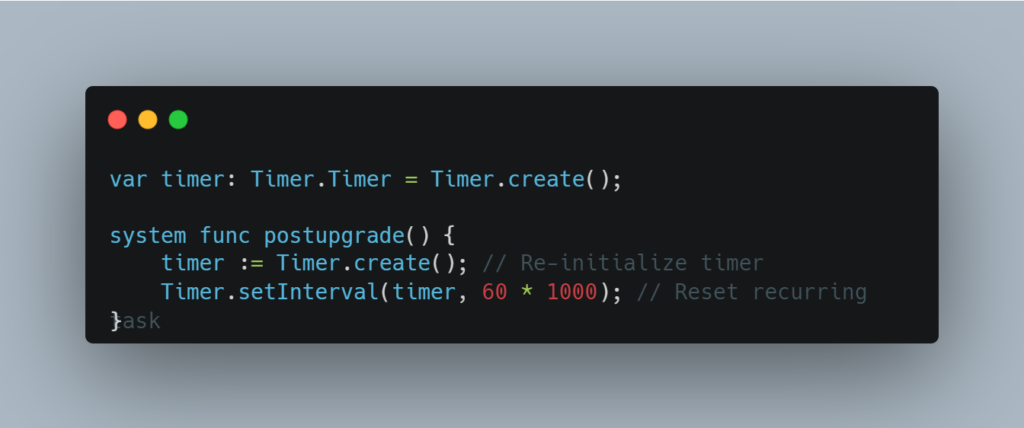
11. Reinstating Timers After Upgrade
Security Concern:
During a canister upgrade, global timers are deactivated. If the canister depends on timers for critical operations (e.g., updating exchange rates in a decentralized exchange), these timers need to be reinstated to ensure smooth functionality post-upgrade.
Example:
A DEX relies on a timer to update exchange rates periodically. After an upgrade, the timer is deactivated, potentially allowing price discrepancies that could be exploited.
Mitigation:
Reinstate timers in the postupgrade hook to ensure that critical operations resume smoothly after the upgrade.
12. Non-Strict Monotonicity of Time
Security Concern:
Timestamps returned by Time.now() can be the same if they occur within the same block. This makes it difficult to ensure the correct sequence of operations, leading to inconsistencies when comparing timestamps.
Example:
If two events occur in the same block and both have the same timestamp, it’s hard to determine which happened first, potentially leading to race conditions.
Mitigation
- Use a State Machine
Instead of relying on timestamps, you can introduce a state machine to explicitly track the progress of operations. This ensures that you can manage the sequence of events clearly and reliably.
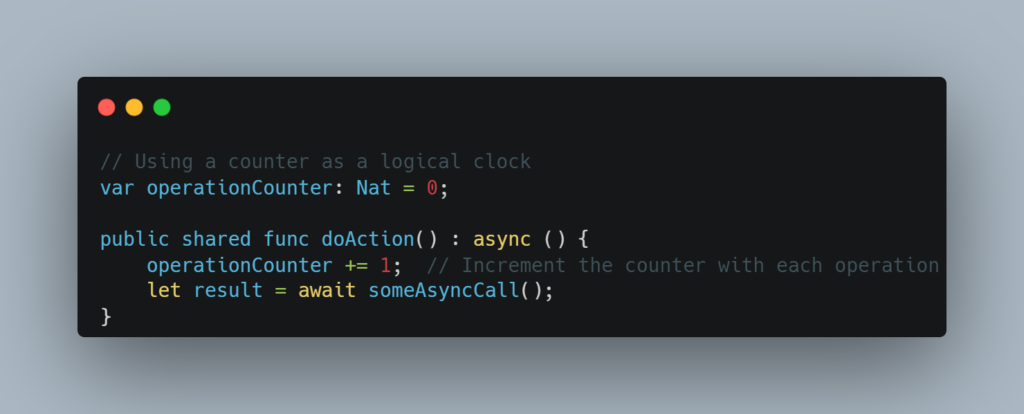
- Use a Counter as a Logical Clock
An alternative approach is to use a counter that increments with each operation or after each await. This counter acts like a logical clock and helps track the order of events more reliably than timestamps.
13. Handling awaits with Time
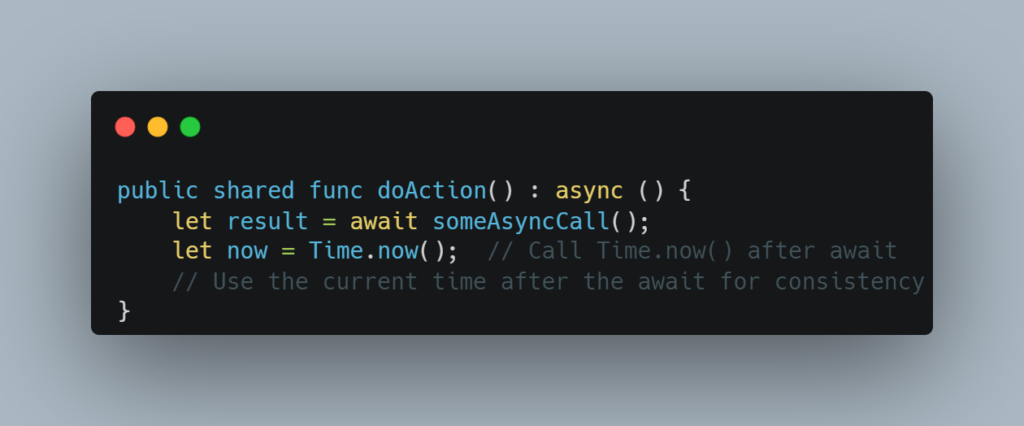
Security Concern:
When using await, the system time may change across the await boundary. If you capture the time before await and use it afterward, the stored time value may no longer be accurate, leading to potential issues with time-based logic.
Example:
A canister captures the current time, awaits an async operation, and then uses the stored time after the await. If the system time has changed, the stored time could be outdated and cause inconsistencies.
Mitigation:
Always capture the current time after an await, not before, to ensure the time value is accurate for the current operation.
14. Cycle Balance Drain Attacks
Security Concern:
In the Internet Computer’s (ICP) “canister pays” model, attackers can deplete a canister’s cycle balance by sending numerous unauthenticated requests or by abusing resource-intensive functions. Without careful handling, this can lead to Denial of Service (DoS), rendering the canister inoperative when it runs out of cycles.
Example:
Imagine a canister that processes small withdrawal requests. If users are allowed to send numerous small transactions (e.g., micro-withdrawals), the canister’s computation cycles will quickly be drained. Similarly, functions that generate referral codes, if not limited, can be exploited by users to create numerous codes, leading to resource exhaustion and upgrade issues.
Mitigation:
- Implement the canister_inspect_message System Method: This system method enables canisters to filter and validate incoming requests before processing them. It helps prevent unauthenticated requests from consuming cycles.
- Cycle Monitoring: Regularly track the canister’s cycle balance to ensure it remains above the freezing threshold and set up alerts for low balance warnings.
- Rate Limiting: Limit the number of requests (e.g., withdrawal or referral code generation) a user can make within a specific time period. This prevents abuse of resource-intensive functions.
- Minimum Transaction Amounts: Set a minimum withdrawal amount to prevent micro-withdrawals that unnecessarily drain cycles.
15. Large Data Attacks
Security Concern:
Large data attacks occur when public methods in a canister allow untrusted users to send vast amounts of data that are stored in the canister’s memory. This poses a potential Denial of Service (DoS) risk. Even though the Internet Computer (IC) has a message size limit of a few megabytes, a user could still repeatedly send large data packets, which accumulate and eventually overwhelm the canister’s memory.
A particularly dangerous form of this attack is the “Candid space bomb,” where a small message can expand into an extremely large value in the Motoko heap, especially when using data types like [Null] or ?t.
Example:
Imagine a canister that allows users to upload documents. If there are no checks on the size of these documents, a malicious user could repeatedly upload large files. Over time, these files fill up the canister’s memory, slowing down performance or even leading to a complete shutdown due to resource exhaustion.
Additionally, the use of unbounded data types like Nat or Int can lead to similar issues. A malicious user could input extremely large numbers, leading to unnecessary strain on the canister’s memory and processing.
Mitigation:
To prevent large data attacks, developers should impose limits on the size of incoming data and validate it before storing it or processing it asynchronously. It’s also critical to avoid using vulnerable data types like [Null] or unbounded Nat and Int values without validation
16. Shadowing of msg or caller
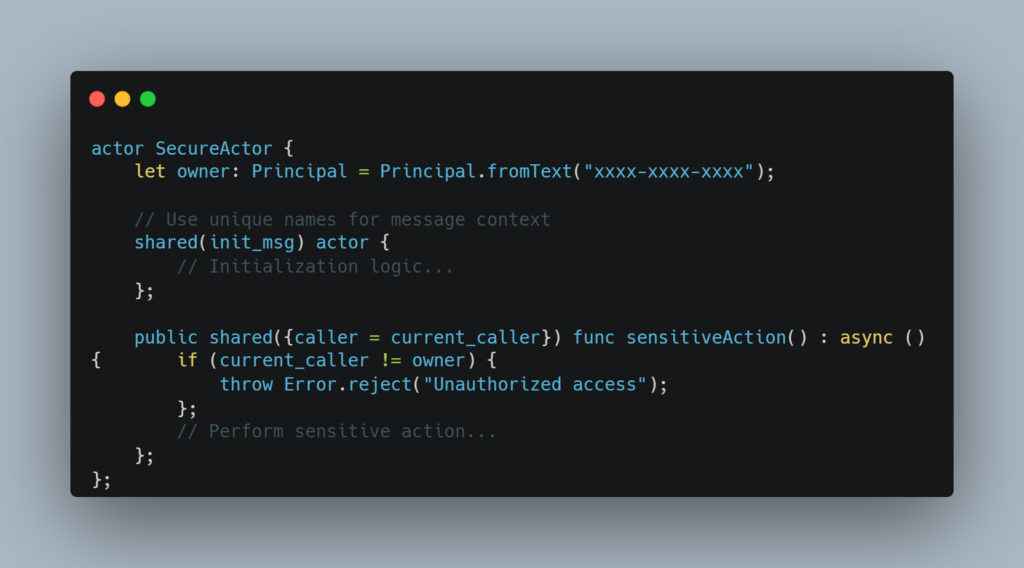
Security Concern:
Shadowing occurs when you use the same variable name in different scopes, which can lead to unintended security vulnerabilities. In the context of a canister, using the same name for the “message context” (e.g., msg) in both the actor and its public methods can be dangerous. If the outer msg is accidentally overwritten or mistyped inside a public method, it might refer to the wrong msg context, leading to an authorization failure or other security issues.
For instance, if msg.caller is supposed to represent the current caller but accidentally refers to the original controller, it can defeat authorization checks, granting access to unauthorized users.
Example:
Imagine a canister where a controller is authorized to perform sensitive actions. If msg is shadowed by mistake, the canister might end up using the wrong msg.caller, allowing unintended access. This could lead to security issues where unauthorized users can invoke sensitive operations.
Mitigation:
To prevent this, always use unique and descriptive names for message contexts. Instead of using msg universally, use distinct names like init_msg or caller_msg. This ensures clarity and reduces the chance of accidental shadowing.
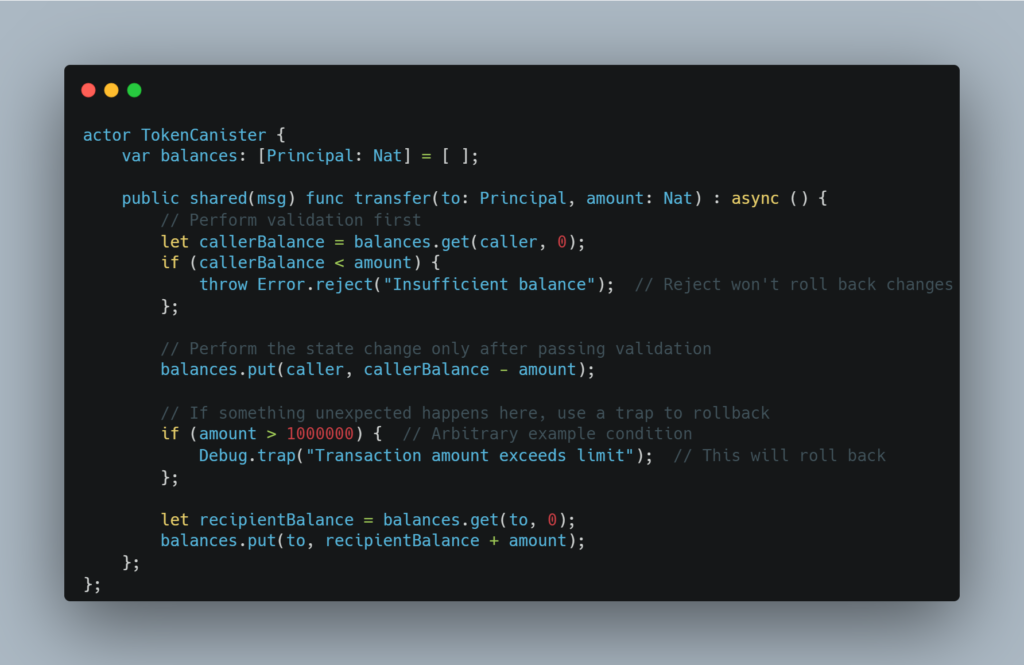
17. Rollbacks
Security Concern:
In canister execution on the Internet Computer, different behaviors can occur depending on whether an operation results in a reject or a trap. When a state change is followed by a throw (reject), the state change is not rolled back. However, if a trap occurs (e.g., through Debug.trap, assert, or out-of-cycle conditions), the state changes are rolled back. This inconsistency can lead to unexpected behavior and security vulnerabilities if not handled carefully.
The critical risk here is that developers may assume that all errors roll back state changes, but this is not true for rejects, which could leave the canister in an inconsistent state.
Example:
Consider a scenario where a canister transfers tokens and performs some validation checks. If an error occurs during validation, the developer may assume that the previous state changes (such as the token deduction) will be rolled back. However, if the error is a reject (e.g., through a throw statement), the token deduction will not be reverted, leaving the canister in an inconsistent state.
Mitigation:
To avoid unwanted rollbacks or unintended state persistence, developers should:
- Avoid state changes before rejects: Perform all validation and error checks before modifying the canister’s state.
- Use traps for critical rollbacks: When you want a state change to be rolled back in case of failure, ensure that the failure is triggered by a trap (such as Debug.trap or assert).
- Audit public update calls: Review all public update calls to ensure no state-changing operations are left in a vulnerable state after a throw.
Case Study: Security Audit of Meta Pool’s StakedICP Protocol
Our audit of Meta Pool’s StakedICP Protocol identified critical security vulnerabilities, particularly in neuron staking, resource management, and canister upgrades. We evaluated the protocol’s ability to handle large-scale staking operations while ensuring the safety of user funds and efficient cycle management. Below are the key findings, including potential risks and actionable mitigation strategies, to improve both the performance and security of your ICP canisters.
The Audit Report link
Key Findings
-
Loss of Protocol Funds Due to Inability to Withdraw Remaining Amounts
Issue:
A critical vulnerability was identified in the protocol’s handling of referral rewards. The remaining amount of rewards was left inaccessible, leading to potential financial loss.
Mitigation:
We recommended introducing a function to withdraw the remaining funds from the deposit canister, ensuring no funds are left locked.
-
Potential Resource Exhaustion & Cycle Drainage
Issue:
Functions like createWithdrawal and getReferralStats posed a critical risk of cycle drainage and resource exhaustion. These functions allowed users to flood the system with small, resource-heavy transactions and excessive referral code generation, leading to a Denial of Service (DoS).
Mitigation:
Rate limiting, minimum transaction amounts, and charging a fee for referral code generation were suggested to prevent resource exhaustion.
-
Cycle Drainage Vulnerability Due to Missing inspect_message Function
Issue:
The canister lacked an inspect_message function, making it vulnerable to unauthenticated cycle-draining attacks. This function would allow early rejection of invalid or malicious requests.
Mitigation:
Implementing the inspect_message function and monitoring cycle balance was recommended to mitigate DoS attacks.
-
Initial ICP Deposit Manipulation Leading to Exchange Rate Exploitation
Issue:
The protocol was vulnerable to manipulation during the first deposit, where an attacker could set an artificially low exchange rate between stICP and ICP tokens, inflating the stICP supply.
Mitigation:
We suggested introducing an initial sacrifice mechanism and using a weighted average approach for calculating the exchange rate.
Conclusion
Securing your ICP canisters is not just a one-time effort—it’s an ongoing commitment to safeguarding your decentralized applications from potential vulnerabilities and attacks. As demonstrated in our audit, even a well-designed system can have critical issues that, if left unchecked, could lead to financial losses, resource exhaustion, or operational downtime.
At BlockApex, we specialize in identifying and mitigating these types of vulnerabilities to ensure your canisters are secure, resilient, and optimized for performance. Our ICP Smart Contract Audit service thoroughly assesses your protocol, helping to safeguard against risks such as cycle drainage, inconsistent state management, unauthorized access, and resource depletion.
By partnering with us, you can ensure that your applications on the Internet Computer are fully fortified against today’s and tomorrow’s challenges.